
IoT
-
IoT
Internet-of-Things (IoT) Project Description:
The Internet of things is the interconnection of physical objects using an internet connection, allowing them to interact external to themselves by sending and receiving data. The project uses ChipKit WiFIRE board designed by Imagination Company and sets up a Creator IoT Framework system. ChipKit WiFIRE is pin-compatible with 3.3 Arduino shields; it can also use IDEs with hardware abstraction (MPIDE, UECIDE). iNet
-
iNet
Network Planning and Design Project Description:
This is a practical and comprehensive project which design an enterprise network from scratch. Students need to design and present a proposal for purchase, implementation and support of the network and make sure the designed network is reliable, secure, and manageable. AI
-
AI
Human-Robot Interaction (HRI)
Project Description:
The main goal of HRI is to enable robots to successfully interact with humans. As robots increasingly make their way into functional roles in everyday human environments (like homes, schools, and hospitals), we need them to be able to interact with everyday people. Moreover, a person working with a robot shouldn’t be required to learn a new form of interaction. Thus, the project aims to develop techniques to improve task coordination and collaboration between human and robot partners. Programmed I/O
-
Q
Why is programmed I/O used mainly for keyboard input, rather than for other I/O devices such as printers and displays?
Explanation:
Programmed I/O is only suitable for individual data word transfers – a full fetch-execute instruction cycle is performed for every data word transfer, and so programmed I/O is slow. For keyboard input, this is not a problem – although programmed I/O is slow compared with the computer itself, it is still much faster than even the most proficient user typing characters at the keyboard. Because the data being transferred are simply individual characters arriving relatively slowly, programmed I/O is suitable for use with keyboards.
Devices such as printers and displays require faster data transfers than would be possible using programmed I/O, because they work with large blocks of data – it would be very inefficient to transfer these large blocks one data word at a time. Interrupt
-
Q. A program is executing when a number of interrupts occur:
- Interrupt B
- followed by Interrupt A
- followed by Interrupt C
(Assume that interrupts A, B and C originate from different devices and therefore require the attention of different interrupt routines.)
Draw a diagram to show the sequence of events for dealing with these interrupts, given the following information:
- Interrupt A has the lowest priority and interrupt C the highest priority.
- Interrupts A and C occur before the interrupt routine for B has finished servicing interrupt B.
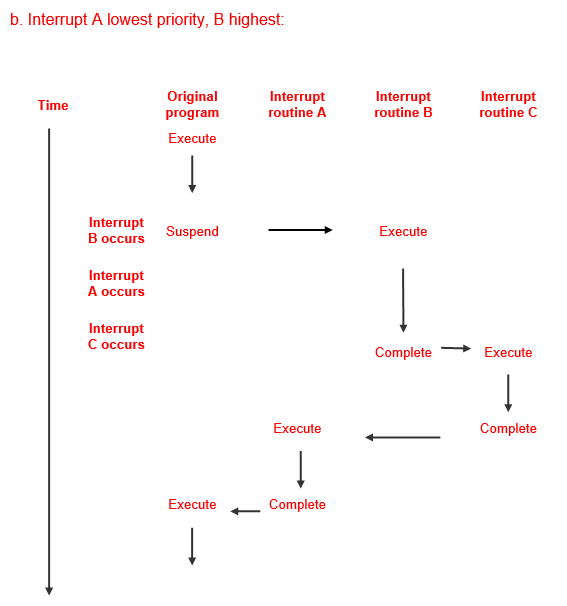
How would the diagram change if interrupt B had the highest priority and interrupt A the lowest?
Explanations: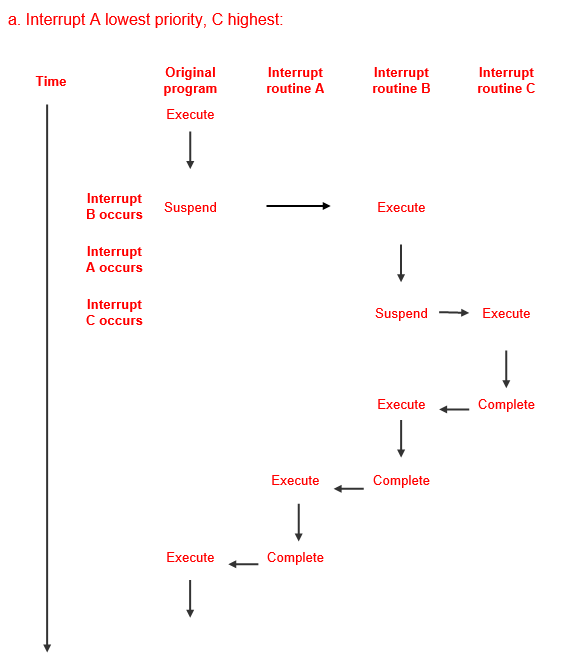
Q. Consider the interrupt that occurs at the completion of a disk transfer and answer the following questions.
- “Who” is interrupting “whom”?
- Why is the interrupt used in this case?
Explanations:A&B: The disk controller interrupts the CPU to notify it that the transfer is complete and the data ready for use. If there were no interrupt capability, the program that is using the data would have to wait long enough to assure that the data transfer is complete, in order to prevent data corruption. But how long is “long enough?”
C. Describe the steps that take place after the interrupt occurs.
When the interrupt occurs, it causes the CPU to suspend execution of the program being executed, then it saves the crucial parameters for later return to that program, and jumps to an interrupt handler program. The interrupt handler notifies the program that the data is available for use. Control is then returned to the program
Role of programmed I/O
-
Q. What role does programmed I/O play in direct memory access?
Explanations:Programmed I/O is used to initiate direct memory access. To initiate DMA, programmed I/O is used to send the following information:
- The location of the data on I/O device
- The starting location in memory
- The size of the block
- Whether it is a read or a write operation
DMA and CPU
-
Q. Assume that a block of data is being written to an output device using DMA. Whilst the data transfer is taking place, the CPU is free to perform other tasks – so it runs another program. Now assume that this program alters the value in one of the memory locations involved in the data transfer. There is no way of knowing whether the data has been altered before or after the transfer of that particular location, so the data transferred to the output device may or may not be the original data. How is such an unstable situation avoided?
Explanations:This unstable situation is avoided by disallowing any modification to the data being transferred. The program waiting for the data transfer is suspended (or, it may perform processing tasks unrelated to the data being transferred). The CPU therefore needs to know when the data transfer is complete, so that it can resume the program that has been suspended. This is achieved using a completion signal interrupt.
Computer Hardware Peripherals
-
Q. Summarise the key differences between primary and secondary storage. Why do computer systems require both primary and secondary storage?
Explanations:- Summarise the key differences between primary and secondary storage. Why do computer systems require both primary and secondary storage?
Primary storage – both cache and conventional memory – is directly accessible by the CPU. Data transfer between primary storage and the CPU is virtually immediate.
Access to secondary storage is much slower. Data and programs in secondary storage must be copied to primary storage to enable the CPU to access them. The advantages of secondary storage are:
- It is non-volatile.
- It can store very large amounts of data.
- It is relatively cheap.
Primary storage is vital because it is only the data and programs stored here that are accessible by the CPU, but secondary storage is also essential because of the need to store large volumes of data indefinitely.
The key point is that no matter where data or programs are stored – on the hard disk, on a CD, or on flash drive, for example – they have to be transferred into primary memory before they can be used by the CPU. Despite innovations such as caching, the underlying model is still exactly the same as that of the Little Man Computer.
- Solid state drives (SSDs) are rapidly replacing magnetic disks as the preferred method of secondary storage in laptops. Why?
Flash memory’s (from which SSDs are made) relatively small size, low power consumption and light weight make it ideal for small devices including smartphones, tablets and laptops. The absence of moving parts also reduces the likelihood of failure due to physical shock and vibration. SSDs generate little heat and no noise.
The cost per byte of SSDs have declined significantly in recent years, increasing their attractiveness as secondary storage devices.
- A magnetic disk spins at 7,200 revolutions per minute. Calculate the disk’s average latency. (Average latency = ½ * 1/rotational speed). Calculate the disk’s transfer time for a single block assuming that each track on the disk contains 30 sectors. (Transfer time = 1/(# of sectors * rotational speed))
7,200 revolutions per minute = 120 revolutions per second. The average latency = ½ x 1/120 = 1/240 secs or 4.2 milliseconds.
Transfer time = 1/(30 * 120) = 1/3600 sec = approx. 0.28 milliseconds
- What is meant by the term seek time in the context of magnetic disks? When will seek time be at its maximum?
Seek time is a reference to the time taken to move the read/write heads from the current track to the track which contains the required data. Seek time will be at its maximum when the read/write heads must move from the outermost track to the innermost track or vice-versa.
- Mirrored arrays can improve both system reliability and disk performance. Explain how these improvements are achieved.
Mirrored arrays consist of 2 or more disks containing multiple copies of the same data. If one disk fails, the data is still available from the other disk(s) thereby ensuring the availability of data. Different blocks of the same file can be read simultaneously from different disks hence reducing the overall time required to read a file. Access time for a multiblock read is reduced roughly by a factor equivalent to the number of disks in the array.
- Striped arrays provide error checking capabilities which allow systems to recover in the event of a disk failure. Explain how these error checking capabilities work.
A striped array requires a minimum of 3 disks. Parity bits are created for each ‘stripe’ and stored on one of the disks or, in the case of RAID5, spread over all the disks. If one disk fails, the missing data can be recreated by comparing the data within the ‘stripe’ that is still available with the parity data. If more than one disk fails, then we are in trouble!
- A true colour image with a resolution of 1,920 x 1,080 pixels (ie high definition) will require how much storage?
How much storage would a true colour, ultra-high definition image (3,840 x 2,160 pixels) require?
A true colour image requires 24 bits or 3 bytes for each pixel. Each byte is used to store details of the intensity of the 3 primary colours, red, green and blue. An image with a resolution of 1,920 x 1,080 pixels will therefore require 1,920 x 1,080 x 3 bytes of storage = 6,220,800 bytes or approx. 6.2MB.
A UHD image will require 3,840 x 2,160 x 3 bytes per image = 24,883,200 bytes or approx. 24.8MB.
- Both inkjet and laser printers use dots to print images on paper. How are those dots transferred onto the paper?
Inkjet printers squirt tiny droplets of boiling ink through nozzles the width of human hair onto the paper. The print cartridge moves across the page while mechanical rollers move the paper downwards.
Laser printers use a photosensitive drum which becomes electrically charged by applying laser light to it. As the drum rotates, toner sticks to the parts of the drum which are electrically charged.
For a fuller explanation, see section 10.7 of Englander.
GCP
-
Google Cloud Platform
Explanations: GCP PUB/SUB
-
Google Cloud Platform Publication and Subscription Services
Explanations: This hands-on lab shows you how to publish and consume messages with a pull subscriber, using the Google Cloud Platform Console
Google Cloud Pub/Sub: Qwik Start - Console
https://run.qwiklabs.com/ Google App Script
-
Google Apps Script and BigQuery
Google Apps Script is a G Suite development platform that operates as a higher-level than if you use Google REST APIs. It is a serverless development and application hosting environment that's accessible to a large range of developer skill levels. In one sentence, "Apps Script is a serverless JavaScript runtime for G suite automation, extension, and integration."
It is server-side JavaScript, similar to Node.js, but focuses on tight integration with G Suite and other Google services rather than fast asynchronous event-driven application hosting. It also features a development environment that may be completely different from what you're used to. With Apps Script, you:
Develop in a browser-based code editor but can choose to develop locally if using clasp, the command-line deployment tool for Apps Script
Code in a specialized version of JavaScript customized to access G Suite, and other Google or external services (via the Apps Script URLfetch or Jdbc services)
Avoid writing authorization code because Apps Script handles it for you
Do not have to host your app—it lives and runs on Google servers in the cloud.
Explanations: App Engine: Qwik Start - PHP
-
Build Apps at Scale with Google App Engine | Google Cloud Labs
Explanations:This hands-on lab at qwiklabs shows you how to create a small App Engine application that displays a short message. Watch the short video Build Apps at Scale with Google App Engine.
Technology
- You are here:
-
Home

- Technology